用Python来找妹子系列 去下点图片
用爬虫来干一件事情
目标
最近听说煎蛋上有好多可爱的妹子,而且爬虫从妹子图抓起,练手最好,毕竟动力大嘛.
而且现在网络上的妹子很黄很暴力,一下接受太多,容易营养不量,但是本着有人身体就比较好的套路,特意分享下用点简单的技术去获取资源
以后如果有机会,再给大家说说日本爱情动作片的种子搜索爬取,多多关注.
干坏事请先准备作案工具
我们只准备最简单的
- python 2.7.11
- Google Chrome
安装的时候记得把pip带上,这样可以方便我们安装一些好用的包,来方便我们干坏事(学习)的过程.
需要用到的包
- 包括更佳符合人类的HTTP库–requests
- 用来解析html文件,快速提取我们需要的内容–beautifulsoup4
也可以用下面的命令快速安装
pip install requests
pip install beautifulsoup4
干正事
从一次正常需求说起
每天在互联网上冲来冲去,浏览着大量的信息,观看这各种鼻血喷发的图片,于是作为新时代青年的我们,怎么能忍受被这些大量的垃圾信息充斥的互联网,我们要反抗,我们要下载.鉴于更为广大的青少年同胞营养快线能够跟得上补给,所以第一篇爬虫小文章.
请看下图,当你在网上冲浪的时候,遇到这样的图片,就问你觉得,虐不虐!虐死了!下不下,下!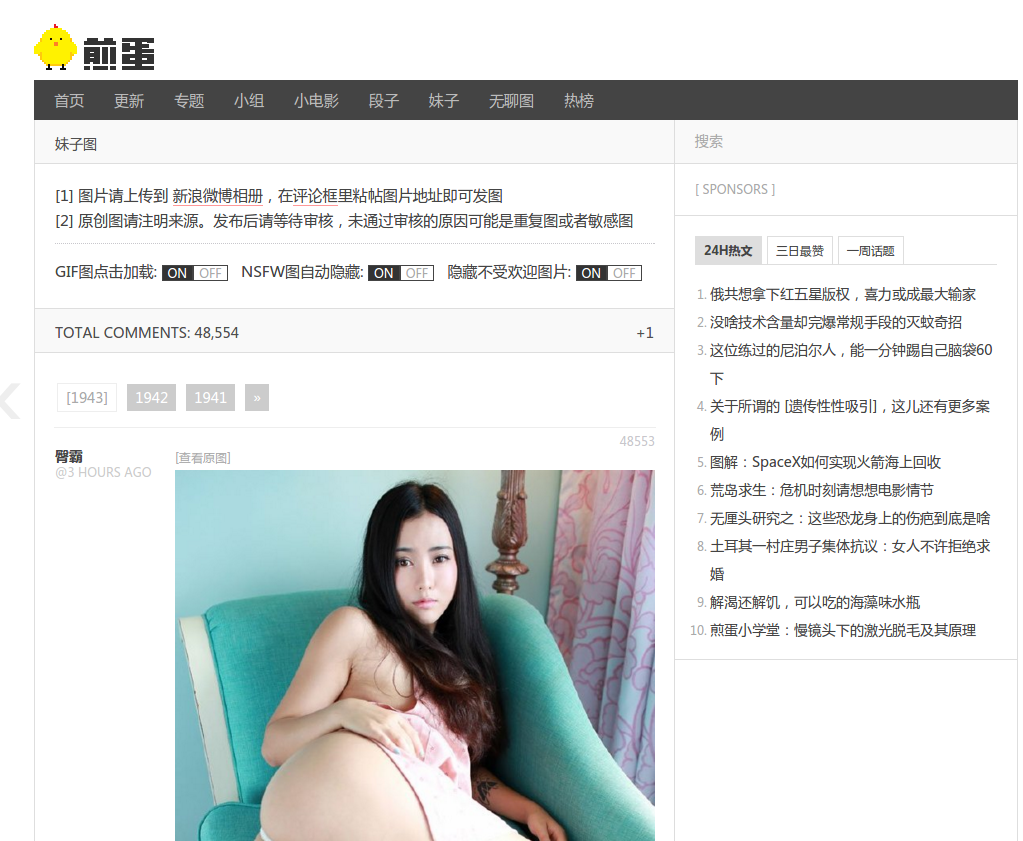
开始干坏事吧, 获取图片的CSS选择器的规则
说干就干,看见这种排版规整,前后有序,不就给我们爬虫练手的最好的机会吗?
首先,我们需要定位我们需要的图片,根据我们之前的准备的作案工具,使用chrome来访问这个网页http://jandan.net/ooxx.
嘿嘿,然后就开始干坏事吧,打开开发者工具 菜单 -> 更多工具 -> 开发者工具,看下图右边的神器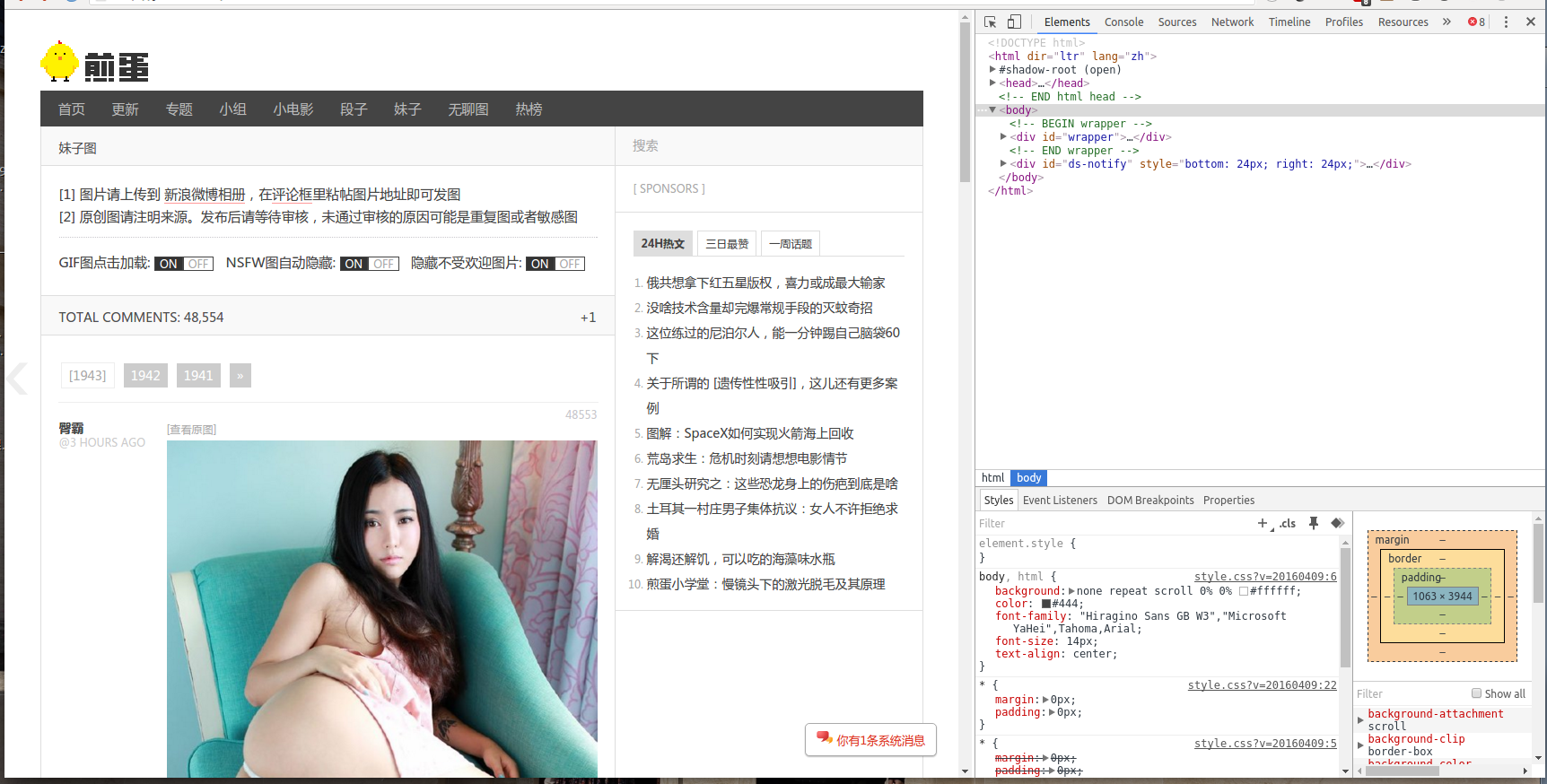
点击这个图标,会出现块选择器,鼠标移动我们感兴趣的部分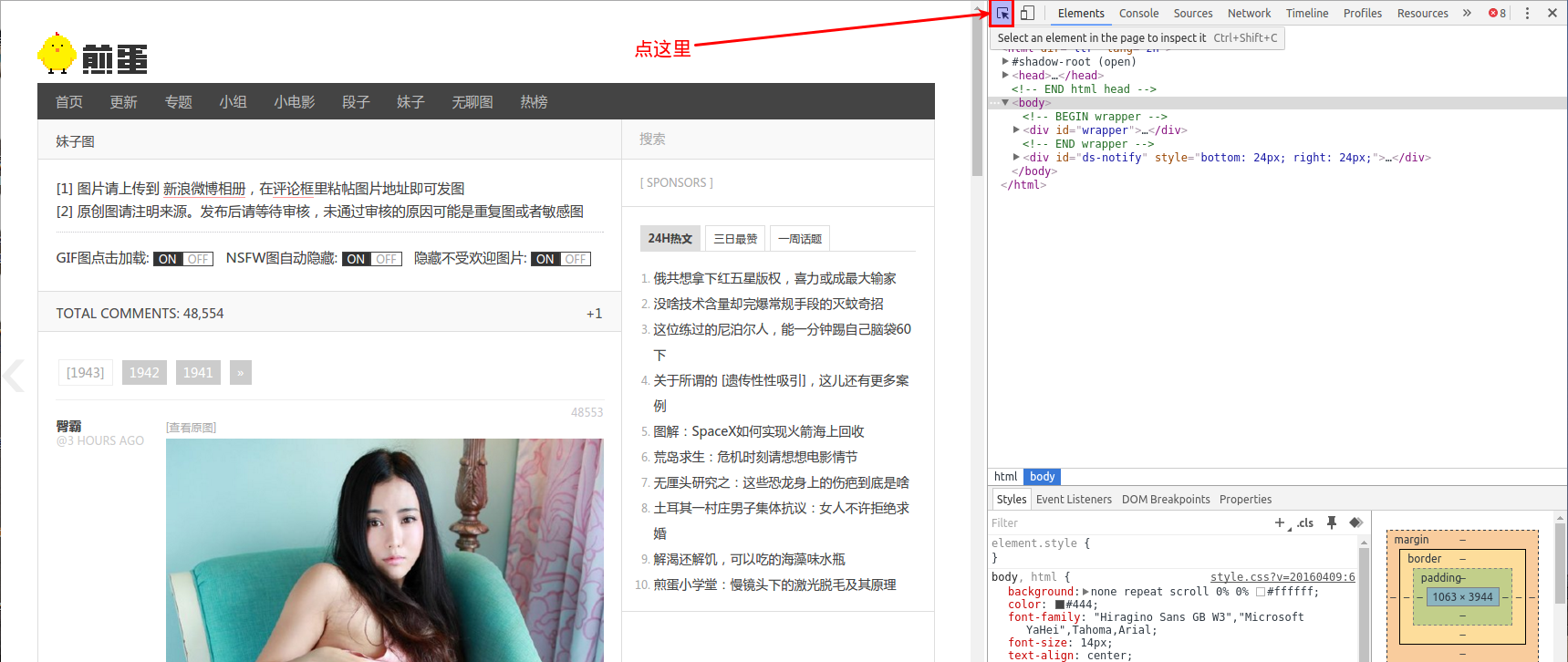
点击区域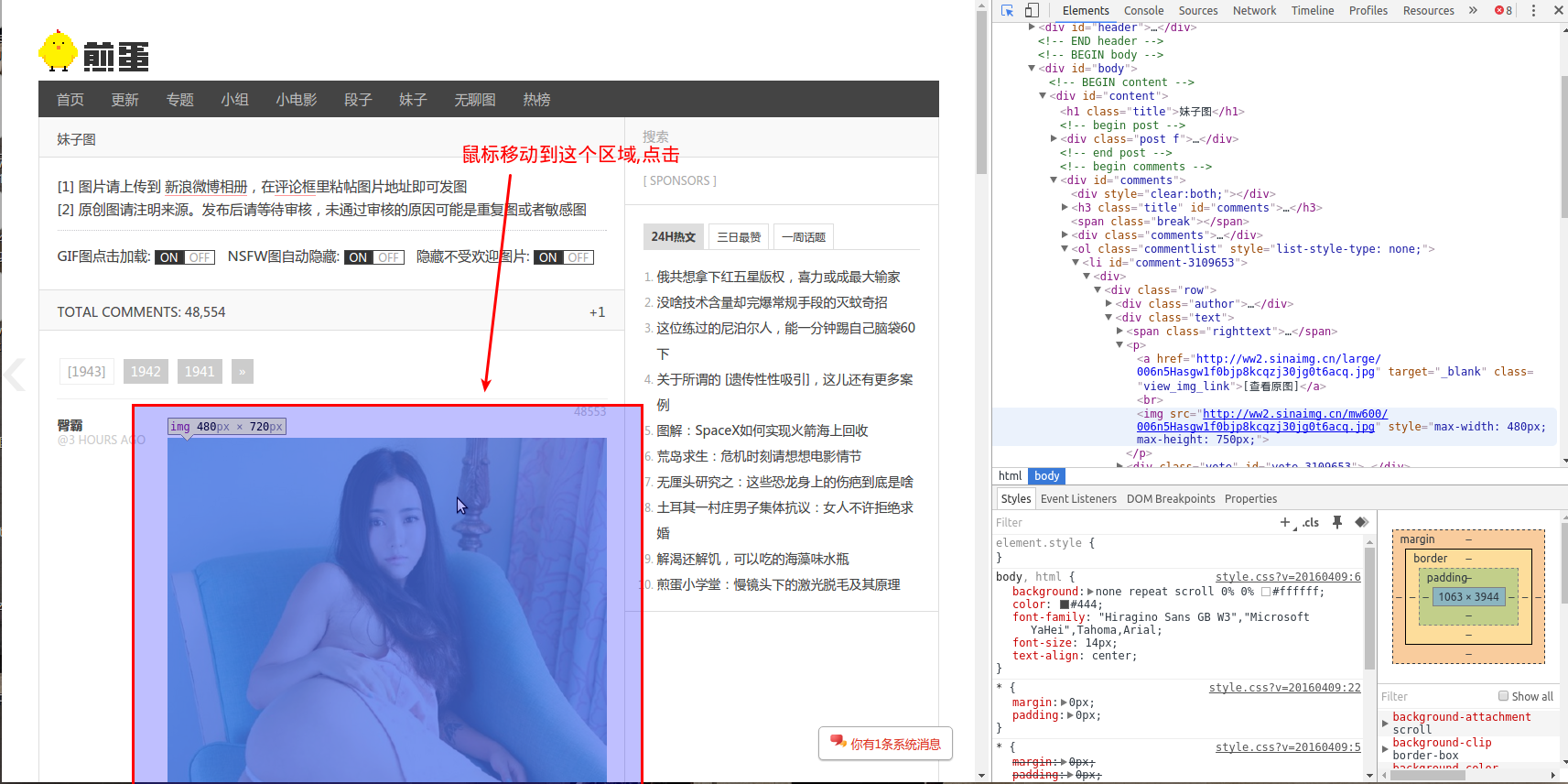
右边神器中就会出现我们所需要的img标签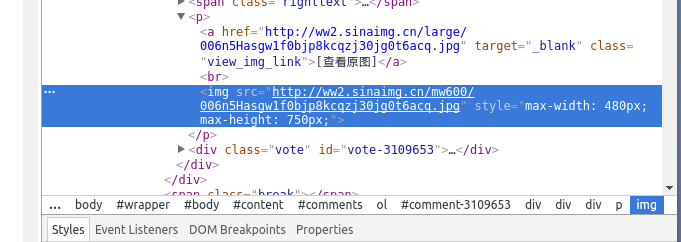
查看之前最后一个以#comments开头的标签, 然后正好它包含了所有img的子标签
下面让我们来一些神秘的事
打开cmd或着终端
输入python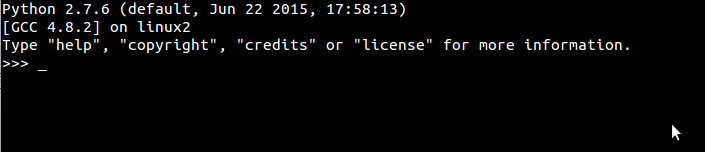
获得神秘第一步
输入以下神秘代码
1 | import requests |
现在偷偷看一下你的当前目录,是不是好羞羞的有很多图片?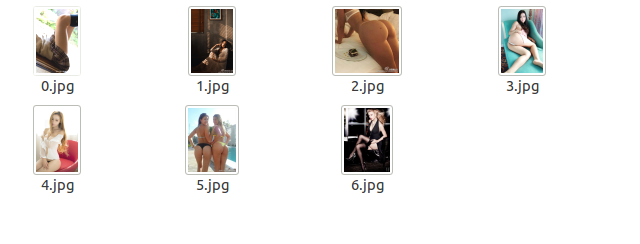
是不是还不够
嘿嘿,今天就到这里了,读取下一页都考你自己探索了,我将会在下个系列给你一个参考方法,希望你持续关注.
概念
最后来点干货,百度抄得,凑字数
网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
